本文介绍Stream模型的功能及使用说明。
背景信息
Stream模型提供子任务生产和消费处理分离的可持续生产消费模式。Produce接口按指定频率持续运行生成一批次子任务信息进入队列,基于缓冲队列框架持续分发子任务给当前业务集群处理。处理分发过程不会等待上一批次执行结束,只要集群有可用机器,资源就会持续分发处理。

该模型主要解决以下问题场景:
现有的Map模型每次运行都需要等待所有子任务执行完,单个子任务耗时影响整体的后续运行。
对子任务的生产速率和分发处理提供全局的并发控制。
调度服务端提供任务运行期的监控报警。
前提条件
已创建应用(任务分组)。具体操作,请参见创建应用。
已接入应用。具体操作,请参见Java应用接入SchedulerX。
使用限制
客户端存在版本限制,具体版本请在以下界面查看:
登录分布式任务调度平台,在左侧导航栏,单击任务管理。
在任务管理页面,单击创建任务。
在创建任务面板,鼠标悬停在执行模式右侧的
 图标处查看客户端版本要求。
图标处查看客户端版本要求。
开发接口
业务开发需要实现接口:com.alibaba.schedulerx.worker.processor.StreamJobProcessor。
接口 | 说明 | 是否必选 |
| 子任务生产方法。 | 是 |
| 子任务处理方法。 | 是 |
| 每批次子任务Reduce方法。 | 否 |
| 是否开启Reduce。 | 否 |
高级配置
登录分布式任务调度平台,在左侧导航栏,单击任务管理。
在任务管理页面,单击创建任务。
在创建任务面板,执行模式下拉列表选择Stream,在高级配置区域配置相关信息。
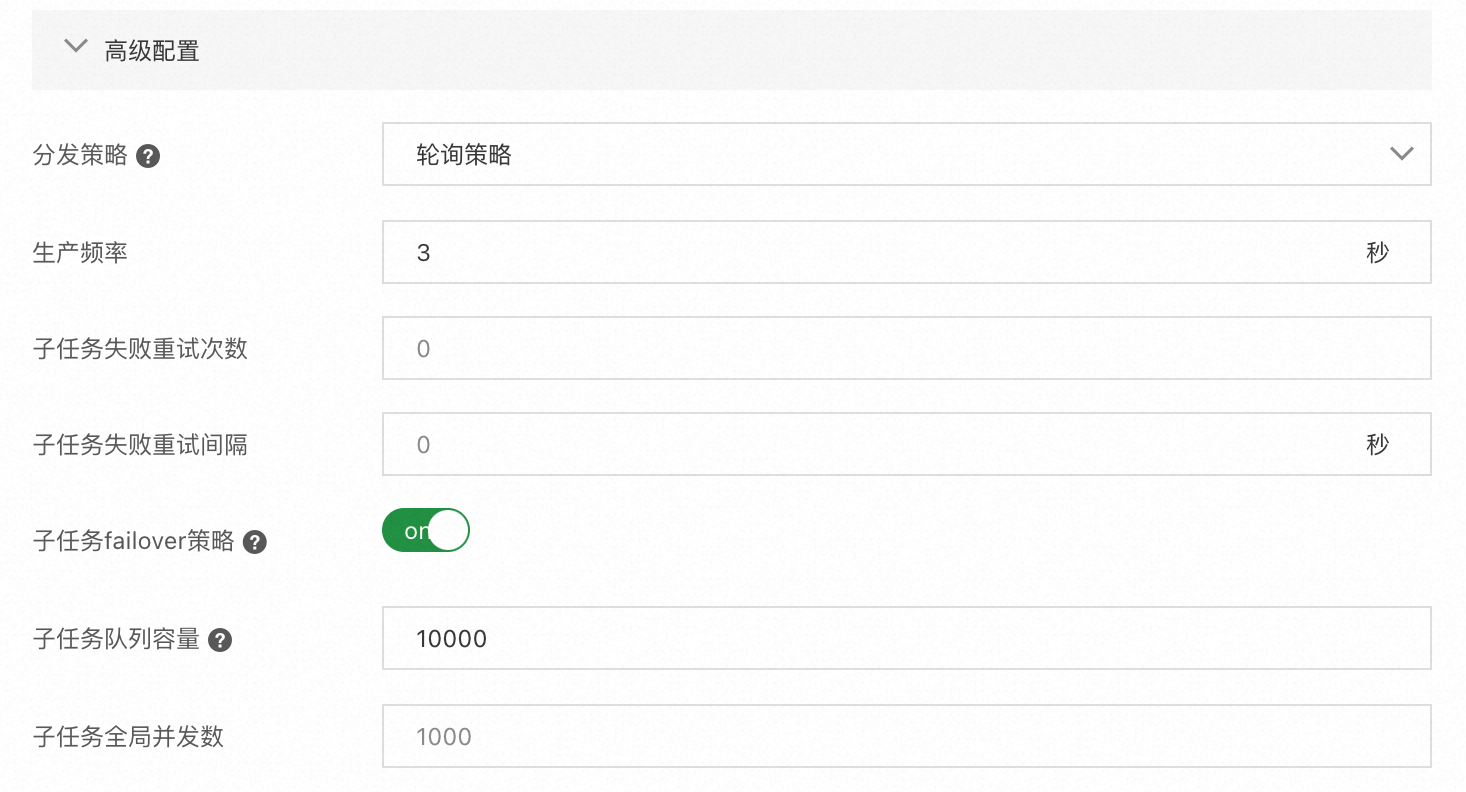
配置项
说明
分发策略
指子任务在业务集群中采用的分发模式。可选项:轮询策略、WorkerLoad最优策略。
生产频率
用于控制Produce方法的循环执行间隔,默认3秒。可根据业务的消费能力适度调整。
子任务失败重试次数
默认为0,子任务失败会自动重试。
子任务失败重试间隔
子任务失败重试间隔,单位:秒。默认为0。
子任务队列容量
生产临时存放的子任务队列。如果队列满了则会阻塞Produce的生产防止消费处理端积压。
子任务全局并发数
流式模型下支持子任务全局并发数功能,该功能可以进行限流,同时配合子任务队列容量控制Produce,默认1000。
限流示例场景:例如下游有性能瓶颈,上千台机器每台机器限制单机子任务并发数为1,还是承受不了大量访问。
实践案例
在您的开发软件(例如IntelliJ IDEA)中,参考以下示例修改应用工程代码。
public class SimpleStreamProcess extends StreamJobProcessor {
private int index = 0;
@Override
public boolean needReduce() {
return true;
}
@Override
public List<Object> produce(JobContext context) {
if (index++ < Integer.MAX_VALUE) {
return Lists.newArrayList(index+"-"+1, index+"-"+2, index+"-"+3, index+"-"+4);
} else {
return null;
}
}
@Override
public ProcessResult process(JobContext context) throws Exception {
Object task = context.getTask();
// 加载子任务进行业务处理
System.out.println(task);
TimeUnit.SECONDS.sleep(1);
return new ProcessResult(true);
}
@Override
public ProcessResult reduce(JobContext context) {
// 获取当前批次的子任务处理结果信息
System.out.println("BatchNo:"+ context.getSerialNum()+ " TaskSize:"+context.getTaskStatuses());
return new ProcessResult(true);
}
}运行查看
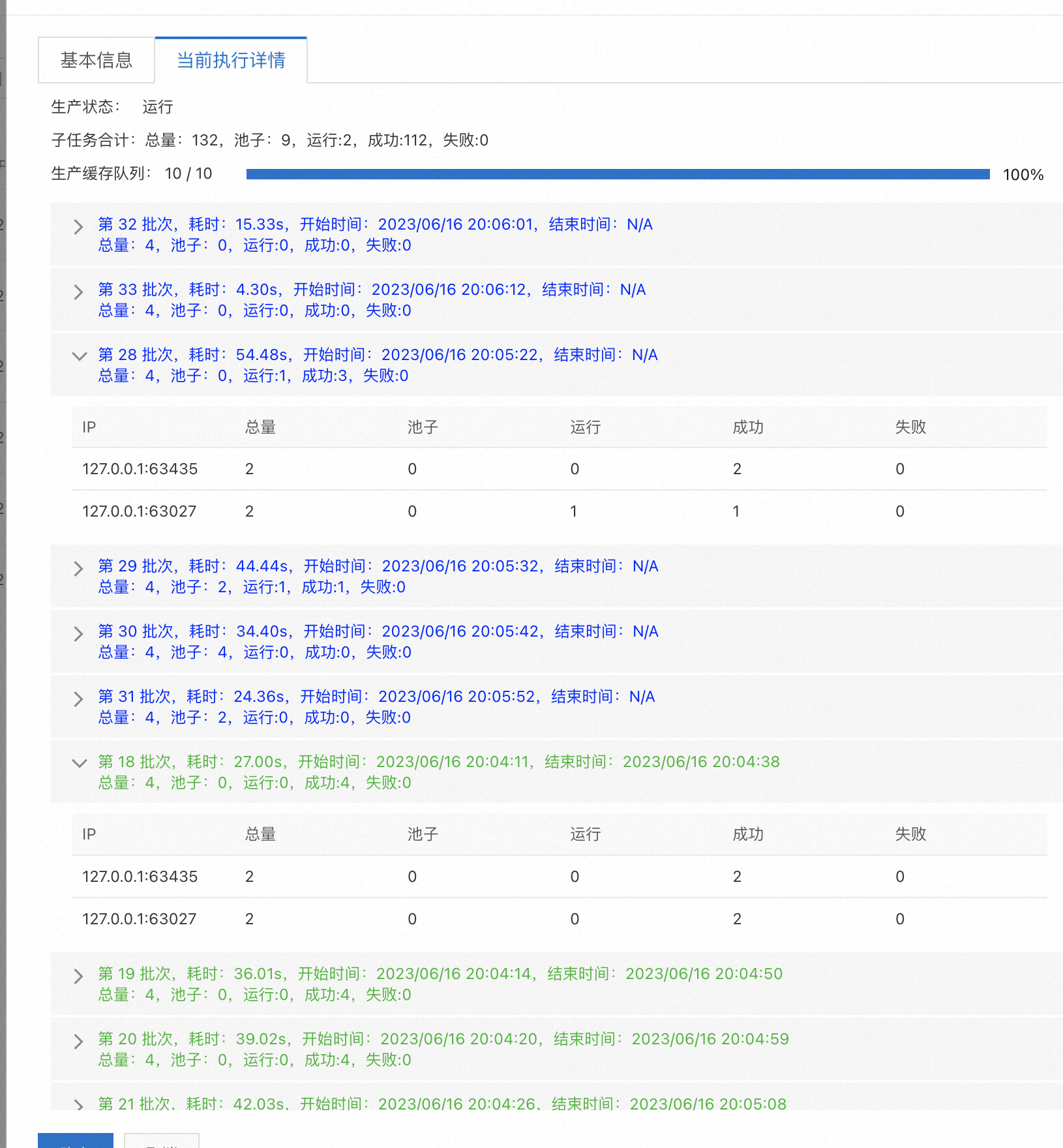
查看执行记录列表,存在一条持续运行中的实例记录。您可在当前执行情况页签,查看当前运行中的每批次执行情况,以及最近10批次历史记录。任务配置失败和超时报警时,根据每个批次是否成功或超时进行相应的报警通知。
- 本页导读 (1)